









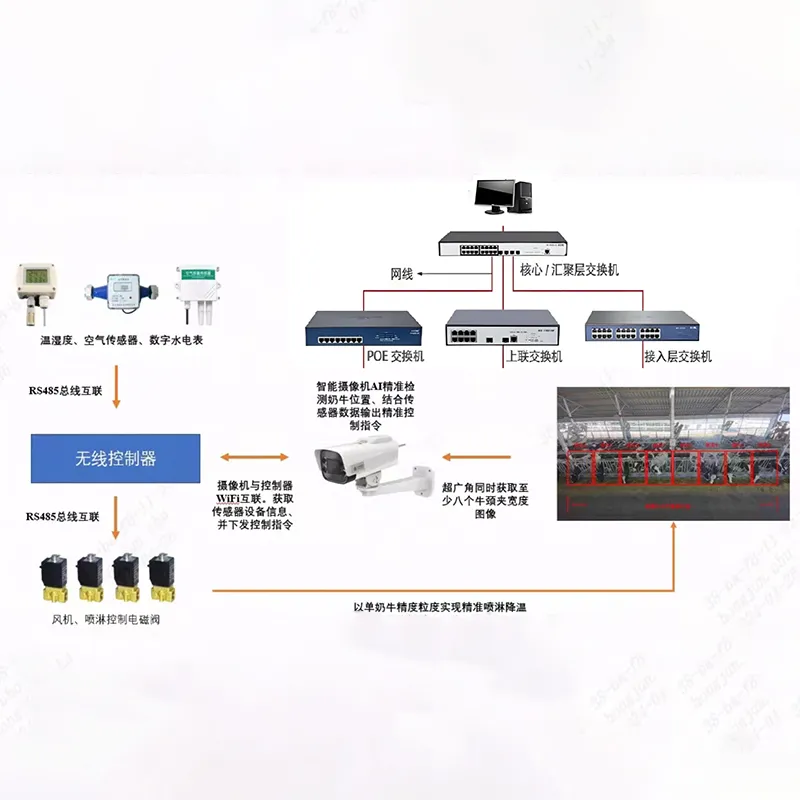
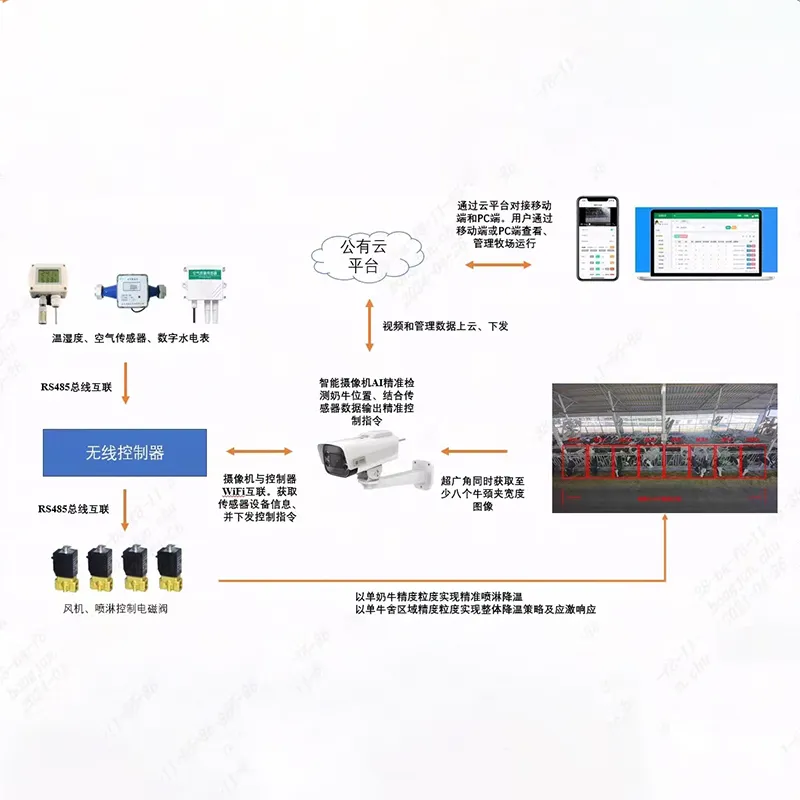
Продукция









Rockchip RK1820 RK1828 Вычислительная мощность NPU: 20 Т
RK1820 – это высокопроизводительный сопроцессор искусственного интеллекта, выпущенный компанией Rockchip, в котором с помощью технологии 3D-многослойной упаковки интегрирована встроенная DRAM с высокой пропускной способностью, Вычислительная мощность NPU достигает 20 TOPS (INT8). Чип спе...
Описание
маркер
RK1820 — это высокопроизводительный сопроцессор искусственного интеллекта, выпущенный компанией Rockchip, в котором с помощью технологии 3D-многослойной упаковки интегрирована встроенная DRAM с высокой пропускной способностью, Вычислительная мощность NPU достигает 20 TOPS (INT8). Чип специально разработан для эффективной работы с большими языковыми и визуальными моделями с размером параметров от 3 до 7 миллиардов на периферийных устройствах (таких как камеры видеонаблюдения, роботы, устройства «умного дома»), обеспечивая локальное вычисление с низкой задержкой и низким энергопотреблением.
RK1820 — это сопроцессор вычислительной мощности, выпущенный компанией Rockchip для эпохи искусственного интеллекта. Он использует передовую технологию 3D-многослойной упаковки и оснащен встроенной DRAM с высокой пропускной способностью (версии 2,5 ГБ и 5 ГБ).
Поддержка моделей: возможность развертывания локальных крупных моделей с количеством параметров до 3 млрд/7 млрд (максимальная длина контекста — 16 тыс. символов)
Производительность: скорость генерации на стороне клиента превышает 100 токенов/с, задержка от клиента до сервера составляет всего 0,1 с
Мультимодальная обработка: поддержка ввода текста, речи, изображений, видео и т. д., совместимость с моделями CNN
Подключение контроллеров: поддержка интерфейсов PCIe 2.0 / USB 3.0, возможность беспроблемной совместной работы с контроллерами RK3576, RK3588 и др.
Экосистема программного обеспечения: совместимость с основными форматами моделей (HuggingFace, PyTorch, GGUF), API-интерфейс, соответствующий стандартам OpenAI, поддержка вызова из C/Python
Благодаря конструкции, сочетающей высокую пропускную способность и низкое энергопотребление, серия RK1820 преодолела ограничения по энергоэффективности и задержкам при развертывании крупных моделей на периферии, обеспечив ИИ-приложениям отзывчивость, сравнимую с облачными решениями.
")
")
связаться с нами
Сопутствующие популярные продукты

Интегрированная машина с большой моделью для интеллектуального захвата голоса
Интеллектуальный речевой улавливающий аппарат с большой моделью обеспечивает преобразование речи ...

Подвесная капсула для БПЛА
Высокоточная трехосевая стабилизированная платформа, оснащенная камерой со 120-кратным гибридным ...

Цифровой домашний шлюз с национальной криптографией
Спецификация конфигурации системы цифрового домашнего информационного блока Общие требован...

Планшет для автомобильной диагностики
Операционная система: Android 7.1 Процессор: Cortex-A17,1.8GГГц Память: 2 ГБ ОЗУ и 64 ГБ ПЗУ ...

Анализатор сети доступа
1.Поддерживает тестирование скорости интернета по кабелю или оптоволокну 10Г и беспроводному 2400...

Интегрированная машина с большой моделью для умных фонарных столбов
Сбор данных видео, аудио и датчиков; обмен данными; безопасность данных; распознавание целей; рас...

Блок диагностики OBD для автомобилей
Два канала КАНФД одновременная поддержка, до 8 Мбит/с ДоИП поддержка, возможность переключения на...

Вычислительные боксы серии Z9 Z96,Z98,Z97,Z9S
№ Категория Характеристики/Функции Z96 Z98 Z97 * Z9S (NP3566) (NP3568) (NP3576) (NP3588S) 1 ...

Вычислительные боксы серии Z2 Z26,Z27,Z2S,Z28,Z216
Категория 1 Категория 2 Характеристики/Функции Z26 Z27 Z2S Z28 Z216 Серия C Системный модуль МП...

Пульт дистанционного управления для БПЛА
Номер Примечание Номер Примечание 1 Антенна 2.4Г/5.8Г 4 дБм 6 Кнопка C2 (функция отсутствует) ...

Съемные модули серии NA NA1812CP, NA1684X
Характеристики Корпус Плата 38 BTB144 Модель чипа NA1812CP NA1684X Главный контроллер CPU 2xR...

Платформенные модули NP серии Европа-Америка NP8MM, NP8MP, NP93, NS135
Характеристики Корпус NCON3239 NCON3741 NCON3036 NCON2630 Модель чипа NP8MM NP8MP NP93 NS135 ...


Съемные модули серии C C26,C27,C2S,C28,C216,C6E,C6P
Характеристики Корпус BTB 5x80pin 85x60x8.9mm BTB 2x 144pin Модель C26 C27 C2S C28 C216 C6E C6...