









интегрированное устройство большой модели на краю (Edge)
Вот все сейчас говорят про интегрированное устройство большой модели на краю, но многие коллеги, кажется, до сих пор путают это с простым запуском облегченной модели на Raspberry Pi. Основная загвоздка не в том, чтобы ?засунуть? модель на устройство, а в том, чтобы заставить связку ?железо-софт-модель? стабильно и эффективно работать в реальных, часто неидеальных, условиях. Я сам через это проходил, когда мы в ООО Шэньчжэнь Энтаймс Технолоджи начинали пилотировать проекты для умных камер в промышленности. Все в теории выглядело гладко, пока не столкнулись с проблемами тепловыделения и прерывистой связи, которые ?съедали? всю предсказательную способность модели.
Что на самом деле скрывается за термином
Когда мы говорим об интегрированном устройстве, речь идет не о коробке с чипом. Это законченный продукт, где вычислительный модуль, память, системы питания и охлаждения, а также программный стек оптимизированы под конкретную задачу большой модели. Например, для анализа видео с дрона в реальном времени недостаточно взять готовый Jetson-модуль. Приходится глубоко дорабатывать драйверы и runtime-окружение, чтобы выжать максимум из аппаратуры и избежать лагов в критический момент.
Частый просчет — недооценка важности pipeline обработки данных прямо на устройстве. Модель — это только ядро. А вокруг нее должен быть выстроен эффективный конвейер: захват данных (скажем, с лидара или камеры), их предобработка (нормализация, обрезка), инференс, а затем постобработка и принятие решения. Если какой-то из этих этапов становится бутылочным горлышком, вся затея теряет смысл. Мы однажды потратили месяц, пытаясь ускорить саму нейросеть, а потом оказалось, что проблема была в медленном коде подготовки кадров, написанном на Python.
Здесь как раз кроется отличие проектной компании вроде нашей от простого интегратора. ООО Шэньчжэнь Энтаймс Технолоджи как раз фокусируется на таком полном цикле: от выбора или проектирования модуля интеллектуальных вычислений до создания готового отраслевого продукта. Это не про продажу ?коробочек?, а про решение задачи клиента, будь то робот или медицинский сканер.
Железо: выбор и компромиссы
Выбор платформы — это всегда боль. NPU, GPU, или специализированные ASIC? Каждый вариант тянет за собой ворота проблем. Возьмем, к примеру, развертывание в автомобильной технике. Требования к температурному диапазону, виброустойчивости и долгосрочной доступности компонентов здесь на порядок выше. Можно взять мощный чип, но если он не сертифицирован для automotive-grade, проект обречен.
В одном из наших проектов для промышленной безопасности мы выбрали, как нам казалось, оптимальный по TOPS (триллионов операций в секунду) процессор. Но в полевых испытаниях выяснилось, что его пиковая производительность достигается только при определенной температуре. При перегреве, который был неизбежен в закрытом боксе летом, скорость падала вдвое. Пришлось на ходу перепроектировать систему охлаждения, что увеличило стоимость и габариты конечного устройства. Это был болезненный, но ценный урок: спецификации на бумаге и поведение в реальном сценарии — две разные вещи.
Сейчас мы чаще смотрим в сторону гетерогенных архитектур, где разные части задачи (предобработка, выполнение модели, логика) распределены между подходящими ядрами. Это сложнее в разработке, но дает более предсказуемую и энергоэффективную работу на краю сети.
Программная экосистема: ад кромешный
Если с железом все более-менее понятно, то софт — это настоящий ад. Фреймворк для инференса (TensorRT, OpenVINO, TFLite), операционная система (часто кастомный Linux), драйверы, менеджеры ресурсов — все это должно работать как часы. И самое главное — обновляться. Как вы будете обновлять весовые коэффициенты большой модели на тысячах разбросанных по заводу устройств? Через OTA? А если канал связи узкий? Приходится разрабатывать механизмы дельта-обновлений и отката.
Помню случай с проектом для беспилотных летательных аппаратов. Мы использовали популярный open-source тулкит для компиляции модели. Все работало в симуляции. На реальном дроне в определенном маневре происходил segfault. Два недели отладки показали, что компилятор оптимизировал одну из операций так, что она давала ошибку при определенных, редко встречающихся входных данных. Пришлось лезть глубоко в документацию компилятора и явно отключать агрессивные оптимизации для части графа. Без детального понимания всего стека, а не только модели, такие проблемы не решить.
Поэтому наша деятельность как проектной компании включает не только производство, но и глубокое проектирование отраслевых продуктов интеллектуальных вычислений, где программная часть проработана не менее тщательно, чем аппаратная.
Сценарии применения: где это действительно нужно
Не всем задачам нужно интегрированное устройство большой модели на краю. Если у вас стабильный широкополосный канал и задержка в секунду не критична, проще гнать данные в облако. Сила края — в отклике в реальном времени и работе в условиях отсутствия связи. Робот на складе, который должен обходить динамические препятствия; умная камера на буровой, которая мгновенно обнаруживает опасность; медицинский монитор, анализирующий ЭКГ прямо у кровати пациента — вот где это оправдано.
В области медицинского оборудования, например, требования к надежности и объяснимости решения модели запредельные. Нельзя просто сказать ?нейросеть так решила?. Нужно предоставлять мета-информацию, коэффициенты уверенности, а само устройство должно иметь соответствующие сертификаты. Это накладывает отпечаток на весь процесс разработки, от выбора обучающих данных до архитектуры системы.
В проекте для головных дисплеев (AR) мы столкнулись с другой проблемой — миниатюризации и энергопотребления. Большая модель для распознавания объектов и их привязки к пространству должна работать часами от небольшой батареи. Это привело нас к исследованиям в области квантования и прунинга моделей прямо на этапе обучения, под конкретные возможности целевого железа. Это уже не просто интеграция, а со-дизайн модели и устройства.
Будущее и практические выводы
Тренд очевиден: модели будут становиться умнее, а устройства — более специализированными. Универсального ?краевого сервера? для всех задач большой модели, на мой взгляд, не будет. Будут появляться оптимизированные решения под конкретные вертикали: одни — для компьютерного зрения в умных городах, другие — для обработки естественного языка в call-центрах на периферии.
Главный вывод для тех, кто хочет заниматься этим всерьез: нельзя отделять data scientist-а, который тренирует модель, от embedded-инженера, который будет ее запускать. Нужна сквозная команда, или хотя бы тесная коммуникация. Модель должна проектироваться с оглядкой на конечную платформу.
Сайт нашей компании, https://www.nnntimes.ru, отражает этот подход: мы позиционируем себя не как поставщики железа, а как партнеры по развертыванию вычислительной мощности в готовые продукты. Успех интегрированного устройства измеряется не тестами в лаборатории, а годами стабильной работы на объекте у заказчика, будь то автономный робот или система промышленной безопасности. И это, пожалуй, самый сложный, но и самый интересный этап во всей этой истории.
Соответствующая продукция
Соответствующая продукция




Самые продаваемые продукты
Самые продаваемые продукты-
 Программный каркас
Программный каркас -
 Алгоритм разделения ролей
Алгоритм разделения ролей -
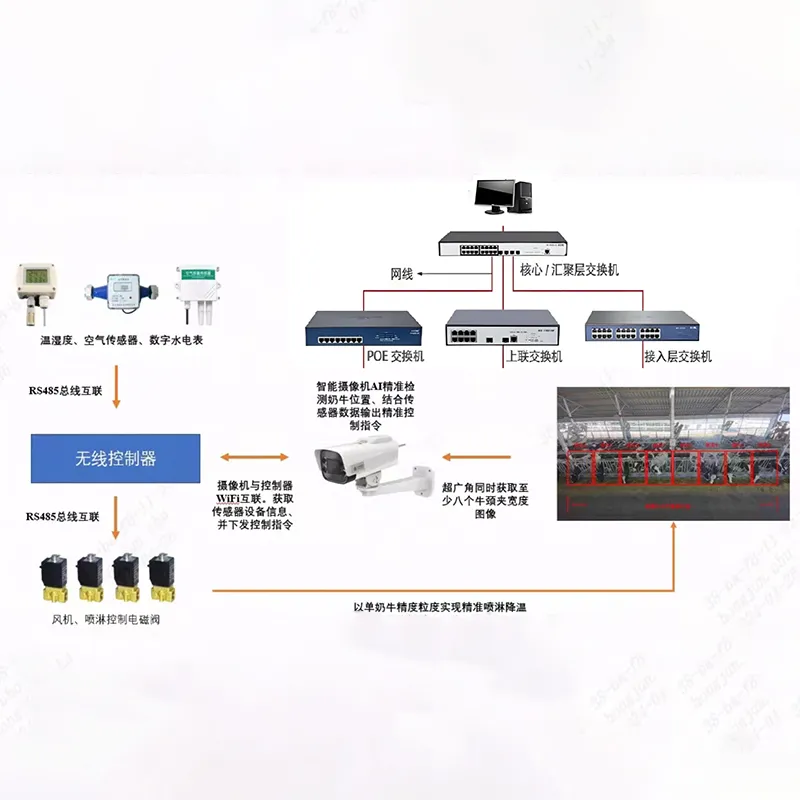 Локальная платформа видеонаблюдения и интернета вещей
Локальная платформа видеонаблюдения и интернета вещей -
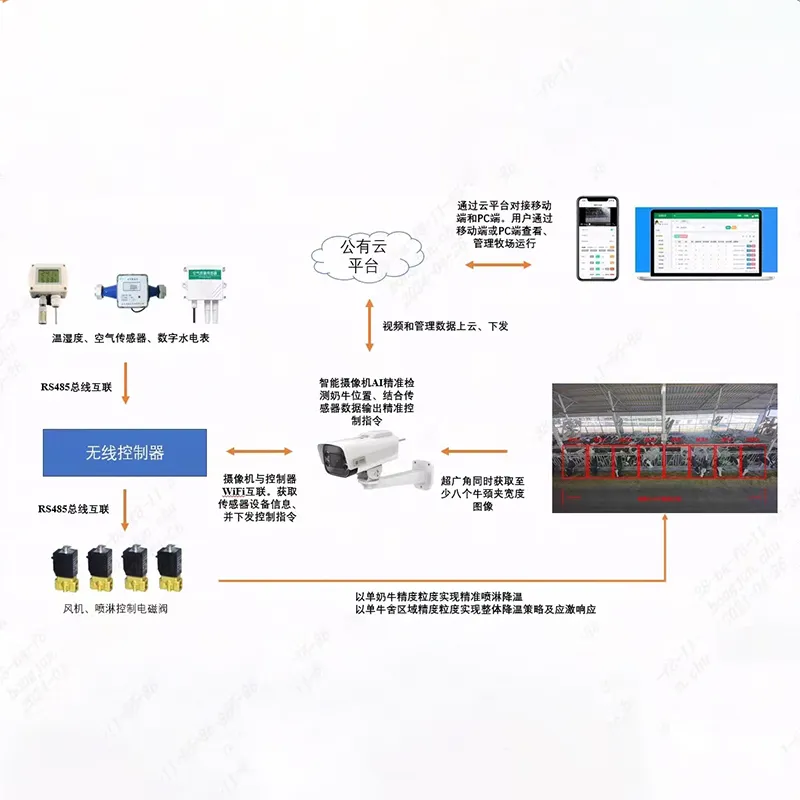 Платформа видеонаблюдения и интернета вещей на общедоступном облаке
Платформа видеонаблюдения и интернета вещей на общедоступном облаке -
 Мобильный наголовный 3D дисплей
Мобильный наголовный 3D дисплей -
 Цифровой домашний шлюз с национальной криптографией
Цифровой домашний шлюз с национальной криптографией -
 Интеллектуальная платформа 80T/128T
Интеллектуальная платформа 80T/128T -
 Подвесная капсула для БПЛА
Подвесная капсула для БПЛА -
 Интеллектуальный вычислительный модуль серия NA NA1126BP,NA186,NA1688,NA6E,NA6P
Интеллектуальный вычислительный модуль серия NA NA1126BP,NA186,NA1688,NA6E,NA6P -
 Вычислительные боксы серии Z9 Z96,Z98,Z97,Z9S
Вычислительные боксы серии Z9 Z96,Z98,Z97,Z9S -
 Блок диагностики OBD для автомобилей
Блок диагностики OBD для автомобилей -
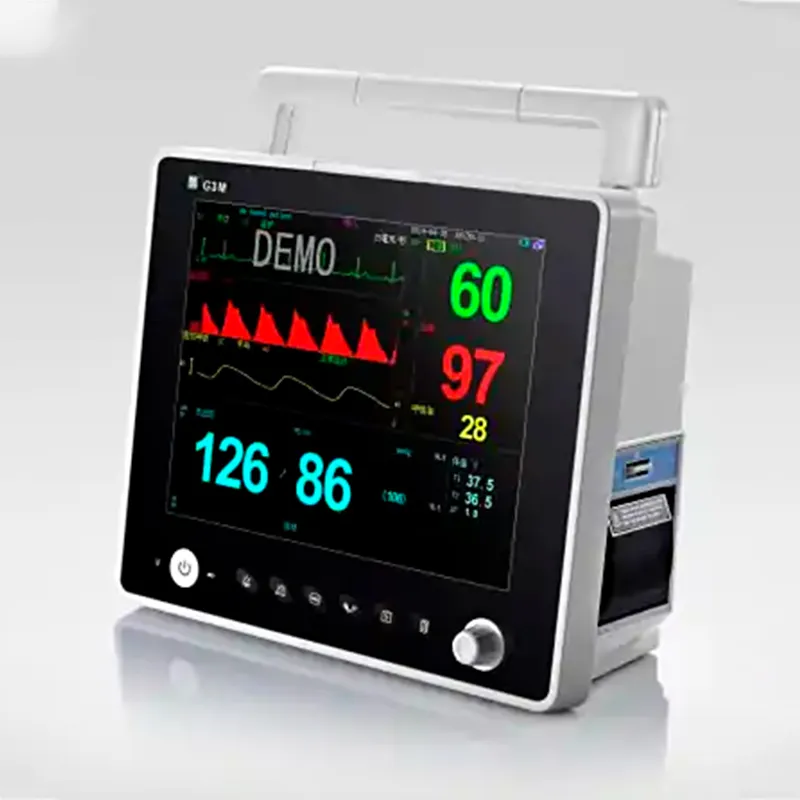
Медицинский монитор
Связанный поиск
Связанный поиск- Профессиональный наголовный дисплей
- Встроенный вычислительный бокс для логического вывода (инференса) большой языковой модели DeepSeek
- 80Т вычислительный бокс
- Портативный наголовный дисплей
- Периферийный интеллектуальный агент
- БПЛА для охранного наблюдения и мониторинга
- Интеллектуальный фонарный столб с высокой вычислительной мощностью
- CV186 SOM
- Бокс для периферийных ИИ-вычислений
- оборудование для управления бпла