









Встроенный вычислительный бокс для локальных больших языковых моделей
Когда слышишь ?встроенный вычислительный бокс для локальных LLM?, первое, что приходит в голову — это, наверное, какая-то универсальная коробочка, куда загрузил модель и она работает. Но на практике всё сложнее. Многие почему-то думают, что главное — это просто упаковать мощный GPU в компактный корпус и дело сделано. Это ключевое заблуждение. На деле, самая большая головная боль — это не железо само по себе, а его интеграция в конкретный продукт, тепловыделение, энергопотребление и, что самое важное, — оптимизация ПО под конкретную задачу. Я видел проекты, где команда купила дорогущий модуль, а потом полгода билась, чтобы заставить его стабильно работать в промышленном шкафу при температуре +50°C. Вот об этих подводных камнях и хочется поговорить.
Суть проблемы: почему ?просто бокс? не работает
Идея локального запуска больших моделей, минуя облако, заманчива: безопасность данных, низкая задержка, независимость от канала связи. Но встроенный вычислительный бокс — это не просто сервер в миниатюре. В контексте, скажем, медицинского оборудования или автомобильной техники, о которых говорит ООО Шэньчжэнь Энтаймс Технолоджи, требования к надёжности, вибрациям и долгосрочной поддержке выходят на первый план. Можно взять отличный чип от Nvidia, но если драйверы и среда выполнения не адаптированы под долгий цикл жизни продукта (5-10 лет), через пару лет обновлений ОС получим неработающую систему.
Один из наших ранних проектов для системы видеонаблюдения как раз споткнулся об это. Мы поставили бокс на базе Jetson, всё отлично работало с современной версией TensorRT. Но когда клиент через год решил обновить безопасность всей системы и поставить патчи на ОС, наш оптимизированный конвейер инференции сломался. Пришлось срочно искать совместимые версии библиотек и фактически проводить ресертификацию всего продукта. Это был дорогой урок, который показал, что локальные большие языковые модели требуют не просто вычислительной платформы, а целостного программно-аппаратного стека с предсказуемой roadmap.
Ещё один нюанс — это разнородность нагрузки. LLM не всегда работают на полную мощность. В том же роботе или БПЛА задачи могут быть разные: распознавание речи, планирование маршрута, анализ сенсоров. И бокс должен эффективно управлять ресурсами, возможно, распределяя вычисления между CPU, GPU и специализированными ускорителями. Просто ?воткнуть? мощный GPU и надеяться на лучшее — путь в никуда. Нужна тонкая настройка, часто на уровне драйверов и планировщиков задач, что требует глубокого погружения в платформу.
Аппаратная платформа: выбор и компромиссы
Сейчас на рынке есть несколько очевидных путей. Первый — это использование готовых модулей типа Jetson Orin или плат на базе Qualcomm. Они хороши своей сбалансированностью и поддержкой. Второй путь — сборка кастомного решения на базе серверных CPU и дискретных GPU, что даёт максимум гибкости и производительности, но убивает компактность и энергоэффективность. Третий, набирающий обороты, — это специализированные NPU или AI-ускорители от компаний вроде Hailo или производителей из Китая.
В работе с Энтаймс Технолоджи, чья деятельность сосредоточена на проектировании отраслевых продуктов, часто приходится балансировать. Для головного дисплея (AR/VR) критична задержка и тепловыделение — там, возможно, придётся жертвовать размером модели в пользу специализированного ускорителя с низким latency. Для промышленной аналитики, где бокс стоит в шкафу, можно позволить себе больше мощности и активное охлаждение, но тогда встаёт вопрос надёжности вентиляторов в условиях запылённости.
Помню случай с проектом для беспилотной тележки на складе. Заказчик хотел, чтобы она понимала голосовые команды рабочих и самостоятельно планировала маршруты, объезжая препятствия. Мы начали с мощного встроенного вычислительного бокса на x86 и дискретной графике. Всё работало, но потребление было под 150Вт, и тележка едва выдерживала 4 часа работы. Пришлось пересматривать архитектуру, выделять задачу распознавания речи на отдельный низкопотребляемый DSP, а для навигации использовать более лёгкую модель, работающую на GPU. Это разделение и стало ключом к успеху. Бокс превратился не в монолит, а в гетерогенную вычислительную систему.
Программный стек: главный скрытый драйвер стоимости
Если аппаратную часть можно, в какой-то мере, купить, то софт — это всегда кастомизация. И здесь кроется до 60% трудозатрат и рисков. Фраза ?поддержка локальных больших языковых моделей? означает на практике: 1) портирование фреймворков (PyTorch, TensorFlow Lite), 2) оптимизацию моделей (квантование, прунинг, компиляция под конкретный ускоритель), 3) создание API и middleware для интеграции с основным софтом продукта.
Очень часто недооценивают второй пункт. Берем, к примеру, LLaMA или какую-то opensource-модель. В сыром виде она требует гигабайты памяти и десятки гигафлопс. Запустить её на edge-устройстве невозможно. Нужно резать, квантовать до INT8 или даже INT4. И вот здесь начинается магия, которая часто превращается в шаманство. Качество модели после агрессивного квантования может просесть в неочевидных сценариях. Мы как-то оптимизировали модель для анализа тональности текста в чате поддержки. На тестовых данных всё было отлично, но в реальной работе она начала сбоить на сленге и опечатках. Пришлось дообучать уже квантованную модель на специфичном датасете, что само по себе нетривиальная задача.
Именно поэтому компании, которые занимаются развёртыванием аппаратного обеспечения, как ООО Шэньчжэнь Энтаймс Технолоджи, вынуждены держать в штате не только embedded-инженеров, но и специалистов по машинному обучению. Без глубокого понимания, как устроена модель внутри, как она реагирует на сжатие, создать стабильный продукт нельзя. Это не просто ?поставь контейнер с моделью?, это кропотливая инженерная работа.
Кейсы и области применения: где это действительно нужно
Глядя на сферы деятельности, которые перечисляет компания — промышленность, автомобили, дроны, роботы, медицина, безопасность — видно, что везде есть своя специфика. В промышленности, например, часто требуется не генерация текста, а анализ логов, предсказание поломок по техдокументации. Здесь встроенный вычислительный бокс должен работать в условиях сильных электромагнитных помех и, возможно, без постоянного интернета для дообучения. Модель должна быть статичной, но очень надёжной.
В автомобильной технике (не путать с ADAS, это отдельная тема) речь может идти о голосовом помощнике или системе анализа состояния водителя. Здесь критична скорость отклика и безопасность. Модель не должна ?задумываться? на полсекунды. И снова приходим к необходимости специализированных ускорителей и жёсткого real-time софта.
Самый интересный опыт у меня связан с медицинским оборудованием для предварительной диагностики по описаниям симптомов. Задача — помочь врачу, а не заменить его. Требования к точности запредельные, а к объяснимости модели — ещё выше. Бокс здесь должен не только выполнять вычисления, но и, возможно, вести аудит всех решений модели для последующего анализа. И да, вся обработка — строго локальная из-за конфиденциальности данных. Это, пожалуй, один из самых чистых примеров, где локальные большие языковые модели не просто удобны, а абсолютно необходимы. Но и сложность такой системы на порядок выше обычного чат-бота.
Будущее и тренды: куда движется edge AI
Сейчас наблюдается явный тренд на специализацию. Универсальный встроенный вычислительный бокс для любых LLM — это миф. Будущее, на мой взгляд, за domain-specific решениями. То есть появятся оптимизированные платформы для медицинских LLM, для промышленных, для автомобильных. Они будут из коробки поддерживать определённый набор моделей и типовых задач, что резко снизит порог входа и стоимость интеграции.
Второй тренд — это гибридные схемы. Не всё должно считаться локально. Часть контекста или сложные задачи обновления моделей могут уходить в облако, а критичные по времени или конфиденциальности инференсы — оставаться на edge. Умный вычислительный бокс будущего будет сам решать, что и где выполнять, исходя из доступности связи, загрузки и политик безопасности.
Наконец, растёт важность инструментов. Если сейчас инженеру нужно быть полубогом, чтобы развернуть и оптимизировать модель на edge, то через пару лет этот процесс должен быть максимально автоматизирован. Что-то вроде AutoML, но для edge-деплоя. Компании, которые смогут предложить не просто железо, а целый ecosystem для лёгкого развёртывания и управления моделями на своих платформах, и будут лидерами. Судя по направлению деятельности ООО Шэньчжэнь Энтаймс Технолоджи — от модулей до проектирования готовых продуктов — они движутся именно по этому пути, закрывая полный цикл от кремния до конечного решения. Это правильный, хотя и очень сложный подход.
В итоге, возвращаясь к началу. Встроенный вычислительный бокс для локальных больших языковых моделей — это не продукт, а целая философия построения автономных интеллектуальных систем. Его успех определяется не гигафлопсами на бумаге, а тем, насколько незаметно и надёжно он работает внутри другого продукта, решая конкретные бизнес-задачи. И это, пожалуй, самая сложная и интересная задача в нашем поле прямо сейчас.
Соответствующая продукция
Соответствующая продукция





Самые продаваемые продукты
Самые продаваемые продукты-
 Подвесная капсула для БПЛА
Подвесная капсула для БПЛА -
 Интеллектуальная платформа 80T/128T
Интеллектуальная платформа 80T/128T -
 Программный каркас
Программный каркас -
 Вычислительные боксы Z4,Z6E,Z6P 32T,80T,128T
Вычислительные боксы Z4,Z6E,Z6P 32T,80T,128T -
 Блок диагностики OBD для автомобилей
Блок диагностики OBD для автомобилей -
 Интегрированная машина с большой моделью для умных фонарных столбов
Интегрированная машина с большой моделью для умных фонарных столбов -
 Цифровой домашний шлюз с национальной криптографией
Цифровой домашний шлюз с национальной криптографией -
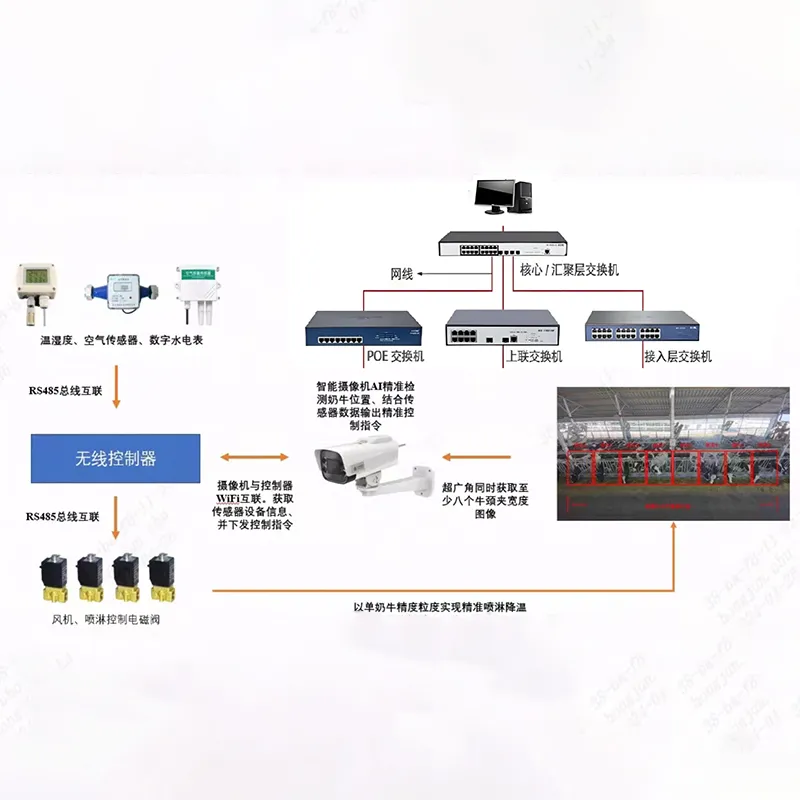 Локальная платформа видеонаблюдения и интернета вещей
Локальная платформа видеонаблюдения и интернета вещей -
 Наголовный 4K гигантский экран 3D плеер
Наголовный 4K гигантский экран 3D плеер -
 Анализатор сети доступа
Анализатор сети доступа -
 Алгоритм разделения ролей
Алгоритм разделения ролей -
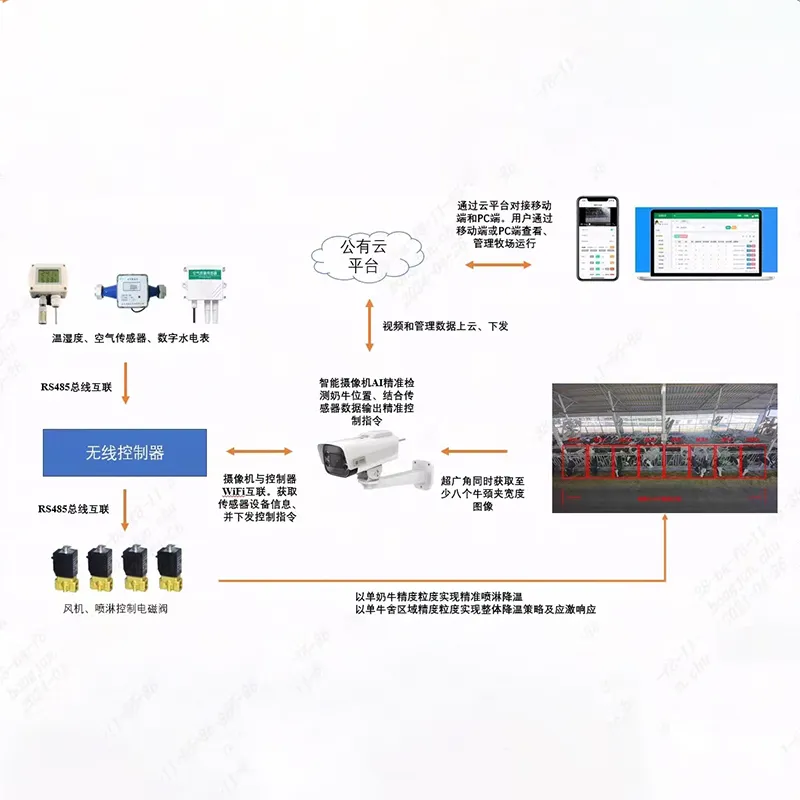 Платформа видеонаблюдения и интернета вещей на общедоступном облаке
Платформа видеонаблюдения и интернета вещей на общедоступном облаке
Связанный поиск
Связанный поиск- Материнская плата для роботов
- Ручной анализатор сети доступа 10G
- RK3568 SOM
- OLED-гарнитура с дисплеем
- Модуль для роботов SOM
- Многопортовый сетевой встроенный вычислительный бокс
- Интеллектуальное устройство для энергетики
- Энергоэффективный встроенный вычислительный бокс
- Встроенный вычислительный бокс для облегченных больших языковых моделей
- Индивидуальная настройка подвеса для БПЛА