









Встроенный вычислительный бокс для облегченных больших языковых моделей
Когда говорят про встроенный вычислительный бокс под LLM, многие сразу представляют себе просто мощный сервер в миниатюре. Это ключевая ошибка. Суть не в упаковке железа в маленький корпус, а в создании специализированной, сбалансированной системы, где каждый ватт и каждый гигабайт памяти работают на конкретную задачу — исполнение облегченной, но все еще ?большой? модели в условиях периферии. Тут и начинаются настоящие сложности, которые в презентациях не показывают.
Где кроется подвох в ?облегченных? моделях
Термин ?облегченная? — слишком расплывчатый. На практике это может означать и модель в 3 миллиарда параметров, и в 7, и даже 13, если мы говорим о квантованных версиях. Основной вызов для встроенного вычислительного бокса — не столько пиковая производительность в TOPS, сколько стабильная работа с большими контекстами и эффективное управление памятью. Однажды мы столкнулись с ситуацией, когда бокс на бумаге идеально подходил под LLaMA 7B, но на реальных длинных диалогах начинал активно свопиться, и latency улетал в небеса. Оказалось, проблема в драйверах и схеме распределения памяти между CPU и NPU. Мелочь, которая стоила месяцев доработки.
Именно поэтому подход ?взять готовый Jetson или что-то аналогичное и запустить? часто проваливается. Аппаратная платформа должна быть спроектирована или, как минимум, глубоко адаптирована под паттерны доступа к памяти, характерные для инференса трансформеров. Это не универсальные вычисления, это специфичная нагрузка, требующая специфичной оптимизации на уровне всей системы — от чипа до системы охлаждения.
В этом контексте интересен опыт компаний, которые изначально смотрят на проблему комплексно. Например, ООО Шэньчжэнь Энтаймс Технолоджи (https://www.nnntimes.ru) в своей работе делает акцент не на продаже ?коробочек?, а на проектировании аппаратного обеспечения под конкретные сценарии периферийного интеллекта. Их профиль — развертывание вычислительной мощности в конечные продукты, будь то роботы, медоборудование или системы безопасности. Такой бэкграунд критически важен, потому что он подразумевает понимание, что встроенный вычислительный бокс для облегченных больших языковых моделей — это не самостоятельный продукт, а компонент, который должен бесшовно встраиваться в более крупную систему, со своими ограничениями по питанию, тепловыделению и физическим интерфейсам.
Железо и софт: история одного неудачного пари
Раньше я наивно полагал, что главное — выбрать правильный чипсет с поддержкой INT8/INT4 квантования. Купили партию модулей с заявленной поддержкой, начали портировать модель. И тут вылезли нюансы: поддержка-то есть, но эффективность операций сильно зависит от их типа и размера тензоров. Некоторые слои модели выполнялись в разы медленнее ожидаемого, создавая ?бутылочное горлышко?. Пришлось вручную переписывать граф вычислений, группируя операции иначе, чтобы загрузить ядра NPU равномерно. Это был тяжелый урок: железо и софт — единый организм. Паспортные характеристики — лишь отправная точка.
Сейчас мы всегда закладываем время на ?притирку? стека: модель (часто в формате ONNX) -> рантайм-инференс (TensorRT, OpenVINO, или проприетарные SDK от вендора чипов) -> драйверы -> сама ОС на устройстве. Каждый слой может внести задержки. Особенно проблемными бывают переходы между разными типами памяти (например, при передаче данных между CPU и акселератором), если шина не оптимизирована под такие потоки.
Кстати, о памяти. Для облегченных больших языковых моделей объем оперативной памяти — не единственный параметр. Важна пропускная способность. Модель в 7B параметров при квантовании в INT4 может ?весить? около 4 ГБ, но для комфортной работы с контекстом в 4K токенов нужно еще столько же, а то и больше, под кэши ключей-значений и промежуточные активации. Если пропускная способность памяти низкая, процессор будет простаивать в ожидании данных. Мы видели кейсы, где апгрейд с LPDDR4 на LPDDR5 на той же частоте CPU давал прирост в скорости инференса на 15-20% просто за счет более эффективной загрузки вычислительных блоков.
Реальные сценарии: не только чат-бот на краю сети
Когда обсуждают применение, все сводят к интеллектуальным ассистентам в автономных устройствах. Это лишь вершина айсберга. Гораздо более требовательные сценарии — промышленные. Допустим, система контроля качества на конвейере с компьютерным зрением, дополненная большой языковой моделью для генерации детальных отчетов на естественном языке о каждом дефекте. Тут нужна не просто генерация текста, а мультимодальность (анализ изображения + язык) и строгое следование шаблону отчета. Задержка критична, но и точность — тоже. Бокс должен работать в условиях вибрации, запыленности, при переменных температурах. Это уже не прототип на столе.
Или медицинские диагностические комплексы. Локальная обработка данных с датчиков и голосовая коммуникация с врачом через специализированную LLM, дообученную на медицинских текстах. Требования к надежности и детерминизму времени отклика здесь запредельные. Просто поставить мощный чип недостаточно — нужна отказоустойчивая архитектура, ECC-память, гарантированные временные циклы обработки. Компании вроде ООО Шэньчжэнь Энтаймс Технолоджи, фокусирующиеся на промышленном, автомобильном и медицинском сегментах, как раз идут от этих жестких требований к проектированию своих центральных контроллеров интеллектуальных вычислений. Их опыт в создании отраслевых продуктов — это готовое понимание данных ограничений, которое затем проецируется и на решения для LLM.
Еще один тонкий момент — энергопотребление. В статике все выглядит хорошо. Но пиковые нагрузки при обработке длинного промпта могут вызывать кратковременные, но значительные скачки потребления тока. Если блок питания или схема управления питанием на материнской плате не рассчитаны на такие пики, устройство может уходить в перезагрузку. Приходится либо ?подкладывать? конденсаторы, либо программно ограничивать тактовые частоты в ущерб производительности, либо глубже оптимизировать сам инференс-движок, чтобы сгладить пиковую нагрузку. Это та самая ?грязная? работа, которая и отличает рабочее изделие от демо-прототипа.
Интеграция как искусство: когда бокс становится ?мозгом?
Самая сложная фаза начинается после того, как сам бокс напечатан и прошит. Его интеграция в конечное устройство. Нужно обеспечить не только физический интерфейс (PCIe, M.2, просто разъемы), но и логический. Как бокс будет получать данные? По какому протоколу? Как возвращать результат? Нужен ли ему постоянный доступ в интернет для редких обновлений модели или достаточно локального хранилища? Здесь мы часто используем подход с выделенным микроконтроллером, который занимается сбором данных с сенсоров и предобработкой, а уже затем передает готовый пакет на встроенный вычислительный бокс. Это разгружает CPU бокса от рутинных задач и позволяет ему концентрироваться на работе модели.
Ошибка, которую мы совершили в одном из первых проектов — попытались засунуть всю логику приложения прямо внутрь среды выполнения модели. Получилась монолитная, сложная в отладке и обновлении система. Сейчас мы строго разделяем слои: аппаратура, инференс-движок с моделью (как сервис), и клиентское приложение, которое общается с этим сервисом через простой API (например, gRPC или даже REST). Это упрощает жизнь: модель можно обновить, перезапустив один сервис, не трогая основное приложение. Такой подход, к слову, хорошо ложится на философию проектирования модулей и контроллеров, которую практикуют в ООО Шэньчжэнь Энтаймс Технолоджи.
И последнее — тестирование. Стресс-тесты должны быть не на синтетических данных, а на максимально приближенных к реальным. Мы записываем реальные диалоги, реальные промышленные сценарии, нагружаем систему 24/7, смотрим на деградацию производительности из-за термотроттлинга, на утечки памяти. Часто баги всплывают только через неделю непрерывной работы. Без такого ?обкатывания? выпускать продукт нельзя.
Взгляд вперед: что будет меняться
Сейчас основная гонка идет в области эффективности. Новые чипы обещают лучшую производительность на ватт, появляются более совершенные методы квантования (например, квантизация до 3 или даже 2 бит). Но я вижу другой тренд — специализация. Уже недостаточно иметь бокс, который ?умеет запускать LLM?. Нужны боксы, оптимизированные под конкретные семейства моделей (скажем, под архитектуру LLaMA или Gemma), или даже под конкретные задачи — например, исключительно для RAG (Retrieval-Augmented Generation) на периферии, со встроенными механизмами эффективного поиска по векторной базе данных.
Вторая большая тема — безопасность и конфиденциальность. Когда обработка данных происходит локально, внутри встроенного вычислительного бокса, это сильный аргумент для корпоративных и государственных заказчиков. Но это накладывает дополнительные требования: аппаратное шифрование данных на накопителе, безопасная загрузка, механизмы защиты от физического вскрытия и извлечения модельных весов. Это целый пласт работы, который только начинает набирать обороты.
В итоге, создание эффективного встроенного вычислительного бокса для облегченных больших языковых моделей — это постоянный поиск компромисса между стоимостью, энергопотреблением, тепловыделением, производительностью и надежностью. Это инженерная, а не научная задача. И успех здесь приходит не к тем, у кого самый современный чип, а к тем, кто глубоко понимает полный стек технологий — от кремния до пользовательского опыта — и способен собрать все компоненты в единое, сбалансированное целое. Именно на этом, судя по их фокусу на проектировании и производстве отраслевых продуктов, и строится работа команд вроде той, что в Шэньчжэнь Энтаймс Технолоджи. Это долгая игра, без быстрых побед, но с реальным impact на то, как ИИ будет работать в мире вокруг нас.
Соответствующая продукция
Соответствующая продукция




Самые продаваемые продукты
Самые продаваемые продукты-
 Наголовный 4K гигантский экран 3D плеер
Наголовный 4K гигантский экран 3D плеер -
 Вычислительные боксы Z4,Z6E,Z6P 32T,80T,128T
Вычислительные боксы Z4,Z6E,Z6P 32T,80T,128T -
 Вычислительные боксы серии Z2 Z26,Z27,Z2S,Z28,Z216
Вычислительные боксы серии Z2 Z26,Z27,Z2S,Z28,Z216 -
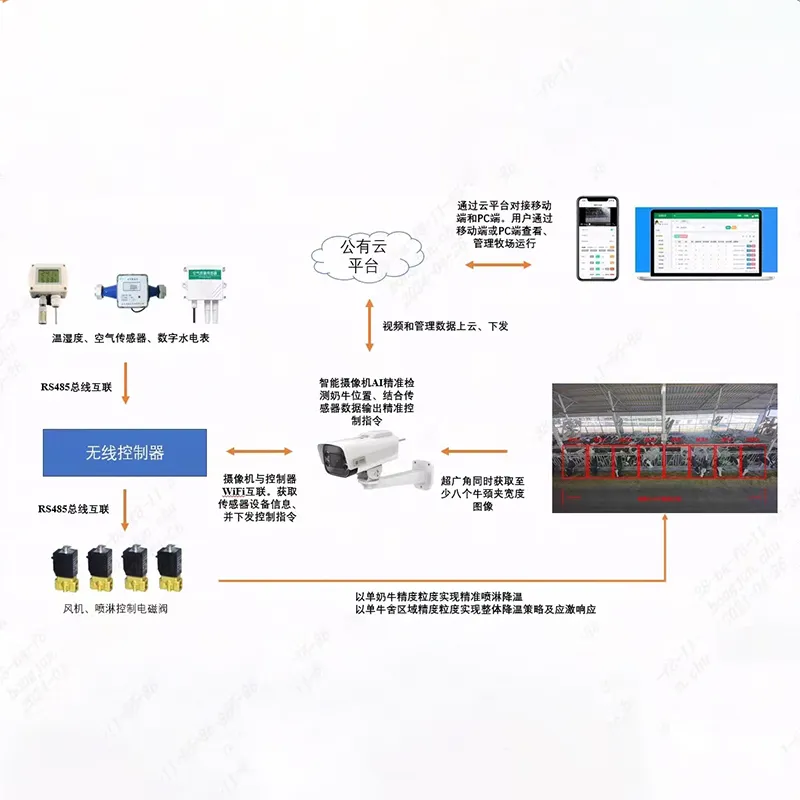 Платформа видеонаблюдения и интернета вещей на общедоступном облаке
Платформа видеонаблюдения и интернета вещей на общедоступном облаке -
 Мобильный наголовный 3D дисплей
Мобильный наголовный 3D дисплей -
 Программный каркас
Программный каркас -
 Анализатор сети доступа
Анализатор сети доступа -
 Наземная станция для БПЛА AheadX
Наземная станция для БПЛА AheadX -
 Блок диагностики OBD для автомобилей
Блок диагностики OBD для автомобилей -
 Планшет для автомобильной диагностики
Планшет для автомобильной диагностики -
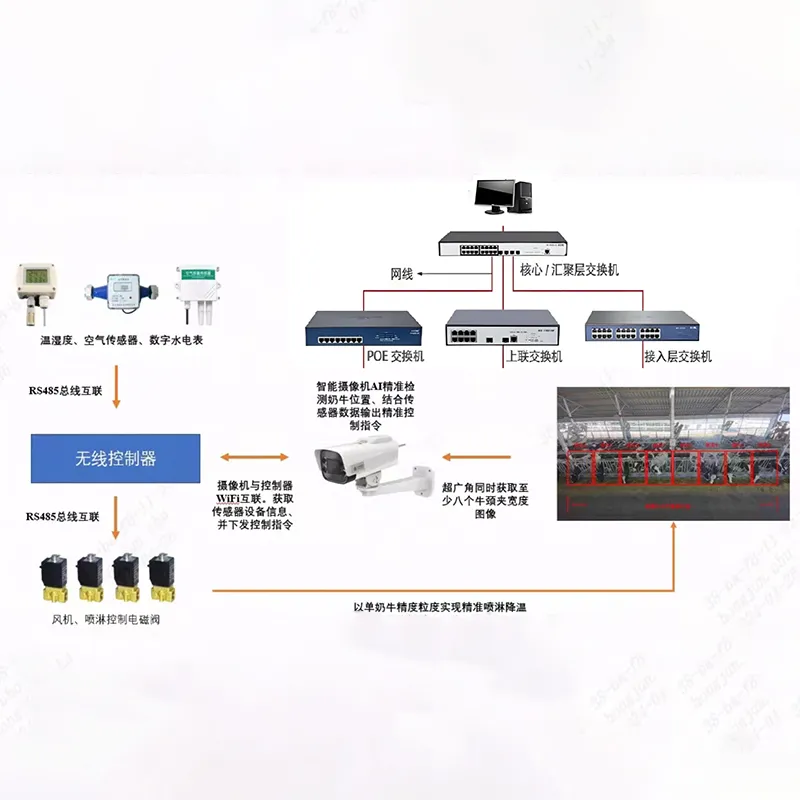 Локальная платформа видеонаблюдения и интернета вещей
Локальная платформа видеонаблюдения и интернета вещей -
 Вычислительные боксы серии Z9 Z96,Z98,Z97,Z9S
Вычислительные боксы серии Z9 Z96,Z98,Z97,Z9S
Связанный поиск
Связанный поиск- Встроенный вычислительный бокс для системы управления БПЛА
- Промышленные БПЛА
- Наголовный дисплей с OLED-экраном
- Периферийное восприятие
- Интеллектуальный агент с круговым обзором 360°
- БПЛА для промышленного инспектирования и контроля
- Иммерсивный наголовный дисплей VR
- Встроенный вычислительный бокс
- 4K наголовный дисплей
- VR головной дисплей