Периферийное (Edge) интегрированное устройство с мультимодальной LLM
2026-06-15
- Что такое периферийное интегрированное устройство с мультимодальной LLM и почему это меняет правила игры в промышленности
- Архитектура и технические требования: что скрыто под корпусом
- Сценарии применения: от контроля качества до предиктивного обслуживания
- Сравнение архитектур: Cloud AI vs Edge AI с LLM
- Интеграция мультимодальных LLM: технические нюансы и ограничения
- Критерии выбора поставщика и оценка совокупной стоимости владения (TCO)
- Безопасность данных и соответствие регуляторным требованиям
- Часто задаваемые вопросы
- Заключение: следующий шаг к цифровой трансформации
Что такое периферийное интегрированное устройство с мультимодальной LLM и почему это меняет правила игры в промышленности
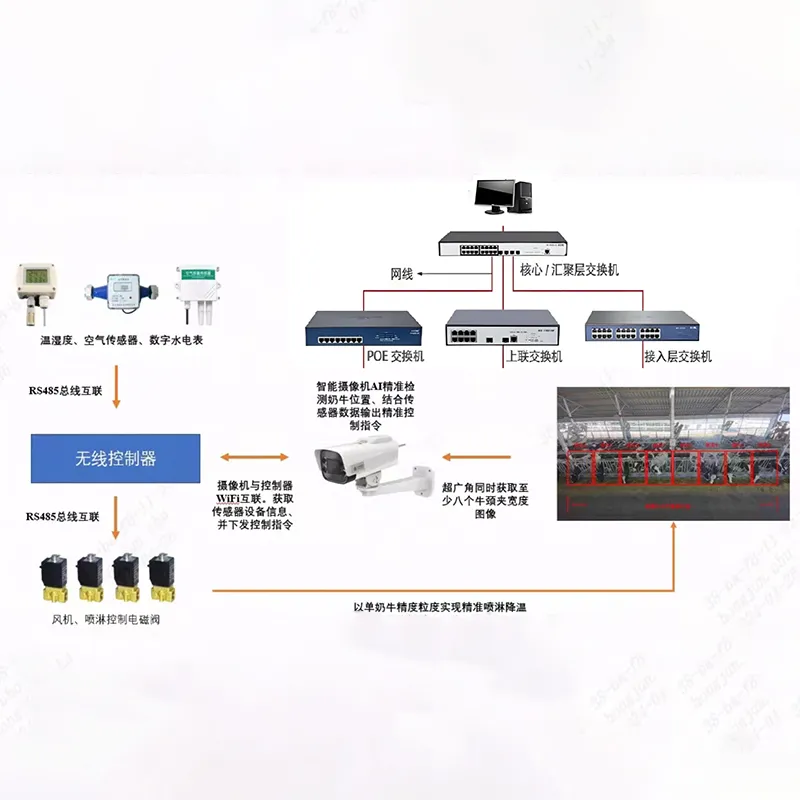
В нашей практике внедрения систем промышленного интернета вещей (IIoT) мы часто сталкиваемся с одной фундаментальной проблемой: задержка данных. Когда видеопоток с камеры контроля качества отправляется в облако для анализа нейросетью, потеря даже 200 миллисекунд может означать брак целой партии продукции или аварийную остановку конвейера. Периферийное (Edge) интегрированное устройство с мультимодальной LLM решает эту проблему кардинально, перенося интеллект непосредственно на заводской цех, к источнику данных.
Это не просто “умная камера” или мощный сервер. Это специализированный вычислительный модуль, способный одновременно обрабатывать текст, изображение, звук и сенсорные данные (вибрацию, температуру) локально, без зависимости от стабильности интернет-соединения. В условиях российских промышленных предприятий, где связь в удаленных цехах или на открытых площадках часто нестабильна, такая автономность становится критическим фактором выживания бизнеса.
Мы наблюдаем переход от простых алгоритмов компьютерного зрения к полноценным мультимодальным моделям. Если раньше система могла только сказать “деталь бракованная”, то теперь, благодаря интеграции большой языковой модели (LLM) на периферии, она объясняет: “На детали обнаружена микротрещина длиной 3 мм в зоне сварного шва, вероятно, из-за перегрева инструмента на 15°C выше нормы”. Эта разница между констатацией факта и диагностикой причины — есть главная ценность технологии.
Для технических директоров и инженеров АСУ ТП понимание архитектуры таких устройств является первым шагом к модернизации. Не стоит воспринимать Edge-устройства как замену облачным хранилищам; это фильтр и аналитический центр первого уровня. Правильный выбор hardware-платформы определяет, сможете ли вы масштабировать решение с одного станка на весь завод без экспоненциального роста затрат на bandwidth.
Архитектура и технические требования: что скрыто под корпусом
Выбор периферийного устройства начинается не с бренда, а с понимания того, какие задачи будет решать мультимодальная модель. LLM требуют значительных вычислительных ресурсов, особенно при работе в режиме реального времени. В отличие от традиционных CNN (сверточных нейронных сетей), которые оптимизированы только для изображений, мультимодальные модели должны держать в оперативной памяти веса для обработки текста и графики одновременно.
Ключевым компонентом здесь является NPU (Neural Processing Unit). Мы рекомендуем обращать внимание на устройства с производительностью не менее 30 TOPS (триллионов операций в секунду) для базовых задач распознавания объектов и до 100+ TOPS для сложного мультимодального анализа. Однако TOPS — это маркетинговая метрика. Реальная производительность зависит от пропускной способности памяти. Если память узкая, процессор будет простаивать в ожидании данных. Поэтому стандарт LPDDR5 или выше является обязательным требованием для современных Edge-решений.
Охлаждение — второй критический параметр, который часто игнорируют при закупках. Промышленное Edge-устройство работает 24/7. Пассивное охлаждение (без вентиляторов) предпочтительнее, так как исключает попадание пыли и металлической стружки внутрь корпуса. Но для мощных чипов с TDP выше 15 Вт пассивного охлаждения может быть недостаточно. В нашей практике был случай, когда клиент установил высокопроизводительные шлюзы в закрытые шкафы без дополнительной вентиляции. Летом, при температуре в цехе +35°C, устройства уходили в троттлинг (снижение частоты), и точность распознавания падала на 40%. Решение потребовало замены корпуса на усиленный алюминиевый радиатор и пересчета теплоотвода.
Интерфейсы ввода-вывода определяют универсальность устройства. Для мультимодальности необходимо наличие:
- Видеовходы: MIPI CSI для подключения нескольких камер напрямую или GigE PoE для сетевых камер.
- Аудиовходы: Качественные ADC (аналого-цифровые преобразователи) для захвата звука оборудования, так как акустическая диагностика часто предшествует визуальной поломке.
- Промышленные шины: RS-485, CAN bus или Modbus TCP для получения контекстных данных от PLC (контроллеров). LLM нужна не только картинка, но и данные о текущей нагрузке двигателя, чтобы сделать точный вывод.
Энергопотребление также играет роль. Типичное промышленное Edge-устройство потребляет от 10 до 60 Вт. При развертывании сети из 50-100 узлов это создает существенную нагрузку на систему бесперебойного питания. Оптимизация энергоэффективности (performance per watt) должна быть в приоритете при сравнении моделей.
Сценарии применения: от контроля качества до предиктивного обслуживания
Теория важна, но бизнес покупает решения конкретных проблем. Рассмотрим два реальных кейса, где внедрение периферийных устройств с мультимодальными LLM дало измеримый экономический эффект. Эти примеры основаны на нашем опыте интеграции на предприятиях металлообработки и энергетики.
Кейс 1: Автоматизированный контроль качества на линии сборки электроники
Клиент столкнулся с высоким уровнем возврата продукции из-за микродефектов пайки, которые человеческий глаз пропускал при усталости. Традиционные системы машинного зрения давали много ложных срабатываний, так как не могли отличить тень от трещины.
Мы внедрили Edge-устройство, подключенное к двум камерам высокого разрешения и датчику температуры платы. Мультимодальная LLM анализировала изображение паяного соединения вместе с данными термопрофиля. Если температура в зоне пайки была на нижней границе допуска, модель интерпретировала даже малейшие визуальные неоднородности как потенциальный дефект “холодной пайки”.
Результаты через 3 месяца:
- Снижение уровня брака на 43%.
- Уменьшение ложных срабатываний с 15% до 2% благодаря контекстному анализу.
- Сокращение времени на ручную перепроверку спорных деталей на 80%.
Важно отметить, что обработка происходила локально. Задержка составляла менее 50 мс, что позволяло механическому манипулятору мгновенно отбраковывать деталь без остановки конвейера.
Кейс 2: Предиктивное обслуживание насосных станций
На удаленной насосной станции в нефтегазовом секторе требовалось предотвратить аварийные остановки. Ранее техник выезжал на объект только по факту поломки или по плану раз в месяц. Вибродатчики передавали сырые данные в облако, но из-за плохой связи пакеты терялись, а аналитика запаздывала.
Было установлено периферийное устройство, агрегирующее данные с акселерометров (вибрация), микрофонов (звук работы подшипников) и датчиков давления. Мультимодальная модель обучалась на нормальных режимах работы. Она выявила аномалию: изменение тональности звука насоса при одновременном росте вибрации на низких частотах, хотя давление оставалось в норме.
LLM сгенерировала отчет на естественном языке: “Обнаружены признаки износа внешнего кольца подшипника №2. Рекомендована замена в течение 72 часов. Риск катастрофического отказа: высокий”.
Экономический эффект:
- Предотвращение простоя стоимостью около 2 млн рублей в сутки.
- Снижение расхода запчастей на 30% за счет перехода от плановой замены к замене по состоянию.
- Экономия на передаче данных: в облако отправлялись только текстовые отчеты и фрагменты аудио при аномалиях, а не непрерывный поток сырых данных, что снизило затраты на связь на 90%.
Сравнение архитектур: Cloud AI vs Edge AI с LLM
Многие руководители задаются вопросом: зачем покупать дорогое железо на периферию, если можно арендовать мощности в облаке? Ответ лежит в плоскости экономики данных и надежности. Ниже приведено детальное сравнение двух подходов для промышленных задач.
| Критерий | Cloud AI (Облачная обработка) | Edge AI с мультимодальной LLM (Локальная обработка) |
|---|---|---|
| Задержка (Latency) | Высокая (200-1000 мс и более). Зависит от качества канала связи. | Крайне низкая (10-50 мс). Данные не покидают локальную сеть. |
| Зависимость от интернета | Критическая. При обрыве связи производство слепнет. | Отсутствует. Устройство работает автономно 24/7. |
| Стоимость передачи данных | Высокая. Передача видео 4K и аудио в реальном времени требует широкого канала. | Низкая. Передаются только метаданные, текстовые отчеты и алерты. |
| Безопасность данных | Риск утечки при передаче. Данные покидают периметр завода. | Максимальная. Чувствительные видео и аудио остаются внутри LAN. |
| Масштабируемость | Легко масштабировать вычисления, но сложно масштабировать канал связи. | Требует инвестиций в hardware на каждом узле, но линейно масштабируется. |
| Сложность обновления моделей | Простая. Обновление на сервере применяется ко всем клиентам сразу. | Средняя. Требуется механизм OTA (Over-The-Air) обновлений для парка устройств. |
Из таблицы видно, что для задач, где важна скорость реакции и конфиденциальность (например, видео с охраняемых территорий или критические производственные линии), Edge-решение безальтернативно. Облако подходит лишь для долгосрочного архивирования и переобучения глобальных моделей на агрегированных данных.
Наша рекомендация: используйте гибридную архитектуру. Edge-устройство принимает решения в реальном времени, а в облако отправляет обезличенные данные для дообучения центральной модели. Раз в неделю обновленная модель загружается обратно на периферийные устройства. Такой подход сочетает скорость Edge и интеллектуальную мощь Cloud.
Интеграция мультимодальных LLM: технические нюансы и ограничения
Работа с большими языковыми моделями на периферии имеет свои подводные камни. Главная проблема — ограниченный объем памяти. Полноценная LLM размером 70 миллиардов параметров не поместится в устройство с 16 ГБ RAM. Поэтому индустрия движется в сторону Small Language Models (SLM) и квантования.
Квантование — это процесс снижения точности чисел, представляющих веса нейросети (например, с 16 бит до 8 или 4 бит). Это позволяет уменьшить размер модели в 2-4 раза с минимальной потерей точности. Для промышленных задач, где требуется четкая логика, а не творческое письмо, модели с квантованием INT8 показывают результаты, сопоставимые с полноточными аналогами.
Однако есть ограничение, о котором нужно знать заранее. Мультимодальные модели на периферии хуже справляются с крайне редкими, нестандартными ситуациями (long-tail events), которых не было в обучающей выборке. В нашей практике был инцидент, когда модель неправильно интерпретировала блик от нового типа защитного стекла на камере как дым.
Как мы это решили? Мы не стали переобучать всю модель. Вместо этого мы настроили систему так, чтобы при низкой уверенности (confidence score < 0.7) устройство отправляло снимок человеку-оператору для верификации. Ответ оператора затем использовался для fine-tuning (точной настройки) локальной модели. Этот цикл "человек в контуре" (Human-in-the-loop) критически важен для поддержания высокой точности.
Также важно учитывать формат ввода. LLM лучше всего работают с текстом. Поэтому перед подачей данных в языковую модель, видеопоток должен быть преобразован в текстовые дескрипторы с помощью визуального энкодера. Качество этого энкодера определяет, насколько хорошо LLM “понимает” картинку. При выборе устройства уточняйте, какой стек ПО предустановлен: поддержка стандартов ONNX Runtime или TensorRT значительно упрощает деплой моделей.
Критерии выбора поставщика и оценка совокупной стоимости владения (TCO)
При закупке периферийных устройств цена “железа” составляет лишь 30-40% от совокупной стоимости владения. Остальные расходы приходятся на разработку, интеграцию, поддержку и электроэнергию. Чтобы избежать скрытых затрат, при выборе поставщика задайте следующие вопросы:
- Поддержка программного стека: Предоставляет ли вендор готовые контейнеры Docker с предустановленными драйверами для NPU? Если вам придется самостоятельно компилировать драйверы под Linux, вы потеряете месяцы разработки.
- Долгосрочная доступность (Longevity): Гарантирует ли производитель поставку той же модели железа в течение 5-7 лет? В промышленности нельзя менять hardware каждые два года, так как это требует повторной сертификации линий.
- Сертификация для РФ: Наличие сертификатов EAC (Евразийское соответствие) обязательно для легальной установки на промышленных объектах. Также проверьте наличие заключения Минпромторга (если требуется для госзакупок или импортозамещения).
- Условия эксплуатации: Соответствует ли устройство стандарту ГОСТ 15150 (климатическое исполнение)? Для неотапливаемых складов требуется диапазон температур от -40°C до +60°C. Обычные коммерческие ПК на этом откажут.
Мы рекомендуем запрашивать пилотный проект (PoC) перед массовой закупкой. Поставьте одно устройство на самый сложный участок производства на 2 недели. Замерьте реальную точность, температуру корпуса и нагрузку на сеть. Только полевые тесты покажут истинную пригодность устройства.
Что касается стоимости, то входной билет в технологию начинается от $500-800 за базовый модуль для простых задач и до $3000-5000 за высокопроизводительные серверные Edge-станции. Однако ROI (возврат инвестиций) обычно достигается за 6-9 месяцев за счет предотвращения простоев и сокращения фонда оплаты труда контролеров.
Пример надежного технологического партнера: ООО «Шэньчжэнь Энтаймс Технолоджи»
Выбор правильного партнера по аппаратному обеспечению может существенно упростить процесс внедрения. В качестве примера компании, глубоко погруженной в специфику периферийных вычислений, можно рассмотреть ООО «Шэньчжэнь Энтаймс Технолоджи». Эта высокотехнологичная инженерная компания, основанная в августе 2020 года в Шэньчжэне, специализируется именно на разработке и промышленном внедрении hardware-решений для Edge AI.
Компания объединяет экспертов с опытом более 30 лет в электронной промышленности и системном проектировании. Их портфель включает съемные системные модули (SOM) серий C26-C216 и специализированные чипсеты с NPU-ускорителями, такими как HUMO Intelligence LQ50 (производительность 100–160 TOPS), что идеально соответствует требованиям сложных мультимодальных задач, описанных выше. Важно отметить, что продукция компании сертифицирована по международным стандартам ISO 9001, IATF 16949 (автопром) и ISO 13485 (медтехника), что гарантирует надежность в жестких промышленных условиях.
«Энтаймс Технолоджи» предлагает полный цикл — от низкоуровневой прошивки до модульной интеграции, поддерживая широкий спектр чипсетов (Rockchip, NXP, Sophon и др.). Их подход, ориентированный на инженерное партнерство и адаптацию решений под конкретные сценарии (от промышленной автоматизации до БПЛА), демонстрирует, как современный поставщик может закрыть не только потребность в “железе”, но и в технической экспертизе на этапе интеграции.
Безопасность данных и соответствие регуляторным требованиям
В эпоху киберугроз промышленные устройства становятся легкой мишенью. Периферийное устройство с LLM — это по сути компьютер, который видит и слышит всё на производстве. Его защита должна быть приоритетом.
Во-первых, убедитесь, что устройство поддерживает Secure Boot (безопасную загрузку). Это гарантирует, что на устройстве запустится только подписанное производителем ПО, и злоумышленник не сможет подменить операционную систему.
Во-вторых, данные должны шифроваться как на диске (AES-256), так и при передаче. Даже если физический носитель будет украден, данные останутся недоступными.
В-третьих, обратите внимание на изоляцию сетей. Edge-устройство должно иметь возможность работать в отдельном VLAN, не имея прямого выхода в интернет, кроме защищенного туннеля для обновлений. Мультимодальная LLM не должна иметь доступа к критическим контроллерам управления станками (SCADA) напрямую, только через односторонние шлюзы данных (data diode) или строгие firewall-правила.
Соблюдение этих требований не только защищает бизнес, но и соответствует растущим требованиям регуляторов в области критической информационной инфраструктуры (КИИ).
Часто задаваемые вопросы
Можно ли использовать обычную веб-камеру с USB вместо промышленных камер?
Для прототипирования — да, но для промышленного внедрения — категорически нет. Веб-камеры не синхронизируются по времени, имеют автофокус, который “дышит” (меняет фокус непредсказуемо), и не защищены от вибраций. Промышленные камеры с интерфейсом GigE или MIPI обеспечивают фиксированный фокус, глобальный затвор (global shutter) для съемки движущихся объектов без смазывания и надежность корпуса IP67. Использование веб-камеры приведет к нестабильности работы LLM и частым ложным срабатываниям.
Сколько времени занимает обучение модели под мои задачи?
Если вы используете предварительно обученную базовую модель (pre-trained model), то этап fine-tuning (дообучения) на ваших данных занимает от 3 до 10 дней. Вам потребуется собрать датасет из 500-1000 примеров ваших конкретных дефектов или ситуаций. Если же задача уникальна и аналогов нет, разработка с нуля может занять 2-3 месяца. Большинство современных Edge-платформ предоставляют инструменты no-code/low-code, позволяющие инженеру-технологу, а не программисту, разметить данные и запустить дообучение.
Что делать, если модель ошибается?
Ни одна модель не дает 100% точности. Ключ к успеху — настройка порогов чувствительности. Лучше получить 5 ложных срабатываний, которые проверит человек, чем пропустить 1 реальный дефект. Внедрите интерфейс обратной связи, где оператор может одним кликом подтвердить или опровергнуть решение ИИ. Эти данные автоматически попадают в набор для переобучения. Через 2-3 недели такой активной работы точность системы обычно превышает 98-99%.
Требуется ли постоянное подключение к интернету для работы LLM на периферии?
Нет. После первоначальной загрузки модели и ПО устройство работает полностью офлайн. Интернет нужен только для периодических обновлений прошивки или отправки агрегированных отчетов в ERP-систему. Это главное преимущество Edge-архитектуры: устойчивость к разрывам связи.
Заключение: следующий шаг к цифровой трансформации
Внедрение периферийного интегрированного устройства с мультимодальной LLM — это не просто покупка нового оборудования. Это переход от реактивного управления производством (“сломалось — чиним”) к проактивному (“знаем, что сломается, и предотвращаем”). Технология позволяет оцифровать экспертный опыт лучших специалистов компании и масштабировать его на каждую единицу оборудования, работающую 24/7.
Мы видим, что компании, которые начинают пилотные проекты сегодня, получают стратегическое преимущество к 2026 году, когда требования к эффективности и качеству станут еще жестче. Не ждите, пока конкуренты внедрят эти решения первыми.
Готовы обсудить архитектуру решения для вашего предприятия? Наши инженеры помогут подобрать конфигурацию hardware и оценят применимость мультимодальных моделей для ваших конкретных задач.
Свяжитесь с нами сегодня для получения технической консультации и расчета стоимости пилотного проекта.
Для более глубокого погружения в тему рекомендуем изучить наши материалы по интеграции IIoT решений и примерам внедрения компьютерного зрения.